
Le traduzioni o versioni della Bibbia possono essere suddivise in due categorie: quelle antiche, importanti soprattutto per la critica testuale, e quelle moderne, che spesso hanno avuto un influsso considerevole nella letteratura e nella lingua in cui furono tradotte.
La traduzione è un'attività che comprende l'interpretazione del significato di un testo ("sorgente", "di origine", "di partenza" o "prototesto") e la successiva produzione di un nuovo testo, equivalente a quello di origine, ma in un'altra lingua (lingua "di destinazione", "di arrivo" o "metatesto"). Il termine "traduzione" tuttavia non indica solamente l'atto del tradurre, ma anche il testo tradotto, risultante da questa attività; per questi motivi, spesso alcuni studiosi e teorici hanno preferito evitare l'ambiguità usando un termine diverso e più specifico: ad esempio, il sostantivo "il tradurre" (Henri Meschonnic) oppure le locuzioni "attività traducente" (activité traduisante), "operazione traducente" (opération traduisante) (Georges Mounin) o altre ancora.
La memoria di traduzione (in inglese translation memory, TM) è un particolare tipo di database utilizzato in programmi software progettati per assistere e aiutare il processo di traduzione. Alcuni programmi che usano memorie di traduzione sono noti come manager di memorie di traduzione (TMM). Le memorie di traduzione vengono tipicamente utilizzate con strumenti dedicati, ad esempio Traduzione Assistita da Computer Computer Assisted Translation (CAT), programmi per la videoscrittura, sistemi per la gestione della terminologia, dizionari multilingue, o anche risultati grezzi di traduzione automatica. L'idea che sta alla base delle memorie di traduzione risale alla fine degli anni settanta, tuttavia queste sono state immesse per la prima volta sul mercato solo alla fine degli anni '80. Una memoria di traduzione è composta da segmenti di testo del brano da tradurre in una lingua emittente e dalle corrispondenti traduzioni in una o più lingue riceventi. Questi segmenti, o stringhe, possono essere interi blocchi di testo, paragrafi frasi o sintagmi. Le coppie che si creano sono chiamate "unità di traduzione". Le singole parole, invece, non vengono gestite direttamente dalle TM, ma da database terminologici. Alcune ricerche dimostrano che molte ditte produttrici di documentazione multilingue usano sistemi di gestione di memorie di traduzioni. In un'indagine su professionisti della traduzione nel 2006, l'82,5% di 874 questionari ha confermato l'utilizzo di TM.L'uso di TM è correlato con tipi di testo caratterizzati da termini tecnici e strutture di proposizione semplici (tecniche o seppure in minor grado, commerciali e finanziarie), buona esperienza nell'ambito dei computer, e ripetitività dei contenutiIl traduttore fornisce al software di gestione della memoria di traduzione un brano origine da tradurre o prototesto. Il programma quindi divide il prototesto in segmenti, ricerca eventuali corrispondenze tra tali segmenti e i segmenti origine precedentemente tradotti e inseriti in memoria di traduzione disponibili, poi propone le corrispondenze trovate come possibili soluzioni di traduzione. Il traduttore può accettare le corrispondenze proposte ovvero sostituirle o modificarle per adattarle meglio al significato del prototesto e utilizzare la versione modificata. Negli ultimi due casi il segmento di prototesto e il corrispondente segmento tradotto metatesto, abbinati, sono inseriti nella memoria di traduzione. Alcuni programmi per la gestione di memorie di traduzione cercano solo le concordanze al 100% (concordanze esatte), vale a dire recuperano solo segmenti di testo che corrispondono esattamente alle unità di traduzione presenti nelle memorie di traduzione. Altri invece utilizzano algoritmi di corrispondenza approssimati, fuzzy: cercano stringhe che corrispondono parzialmente al segmento origine e le propongono al traduttore evidenziando le differenze; questi potrà peraltro impostare nel programma la percentuale di concordanza minima da considerare. La flessibilità e la robustezza degli algoritmi di ricerca delle concordanze determinano ampiamente le prestazioni del programma di gestione della memoria di traduzione, anche se per alcune applicazioni la percentuale di corrispondenze esatte è tanto alta da giustificare l'utilizzo delle sole concordanze esatte. I segmenti che non hanno nessuna corrispondenza in memoria dovranno essere tradotti manualmente dal traduttore. Questi nuovi segmenti tradotti vengono archiviati nel database, dove possono essere utilizzati per traduzioni future e nelle ripetizioni dello stesso brano in corso di traduzione. Le memorie di traduzione sono particolarmente efficienti per la traduzione di testi molto ripetitivi, come ad esempio i manuali tecnici. Sono utili anche per tradurre cambiamenti aggiunti man mano a un testo già tradotto in precedenza, in quanto permettono, per esempio, di trattare un minor numero di cambiamenti in una nuova versione di un manuale. Al contrario, le TM sono tradizionalmente considerate inadeguate per la traduzione di testi letterari per il semplice motivo che in questo tipo di testi la ripetizione è assente, o quasi. Tuttavia, alcuni le trovano utili anche per testi non ripetitivi, perché le risorse database create per le ricerche di concordanza hanno un valore per determinare l'uso appropriato dei termini, per l'assicurazione della qualità (nessun segmento vuoto), e per la semplificazione del processo di revisione (segmento sorgente e destinazione sono sempre visualizzati insieme, mentre i traduttori, in un ambiente di revisione tradizionale, devono lavorare con due documenti).

Il tedesco (; [dɔɪ̯ʧ]) è una lingua indoeuropea appartenente al ramo occidentale delle lingue germaniche. È la lingua con il maggior numero di locutori madrelingua del continente europeo e dell'Unione europea, parlata come prima lingua e riconosciuta come lingua ufficiale in Germania, Austria, Svizzera, Liechtenstein, Namibia (ufficiale come lingua regionale) e nella regione italiana del Trentino-Alto Adige. All'interno del gruppo germanico è la lingua più diffusa nel mondo dopo l'inglese.

La lingua svedese () è una lingua germanica settentrionale parlata da 9,6 milioni di persone, prevalentemente in Svezia (come unica lingua ufficiale, dal 1º luglio 2009) ed in alcune zone della Finlandia (circa il 6% della popolazione soprattutto lungo le coste e nelle isole Åland), dove ha pari diritti legali insieme al finlandese. In gran parte è mutuamente intelligibile con il norvegese, mentre minore è l'intelligibilità reciproca con il danese. Discendente del norreno, lo svedese è attualmente la più parlata delle lingue germaniche settentrionali. Lo svedese standard, parlato dalla maggior parte degli svedesi, è la lingua nazionale evolutasi a partire dai dialetti svedesi centrali nel XIX secolo. Malgrado esistano ancora distinte varietà regionali discendenti dai vecchi dialetti rurali, la lingua parlata e scritta è uniforme e standardizzata. Alcuni di questi dialetti differiscono considerevolmente dalla lingua standard nella grammatica e nel vocabolario, e non sempre sono mutuamente intelligibili con lo svedese standard. Sebbene non siano in pericolo di un'imminente estinzione, simili dialetti sono stati in declino durante il secolo scorso, nonostante siano ben studiati e il loro uso sia spesso incoraggiato dalle autorità locali. L'ordine standard delle parole nella frase è Soggetto Verbo Oggetto, sebbene possa essere spesso modificato per sottolineare alcune parole o frasi. La morfologia svedese è simile a quella inglese; le parole subiscono una minima flessione, ci sono due generi grammaticali, c'è distinzione tra singolare e plurale e non ci sono casi (sebbene vecchie analisi postulino due casi, nominativo e genitivo). Gli aggettivi conoscono una costruzione dei gradi di comparazione analoga a quella dell'inglese ma sono anche flessi secondo genere, numero e determinazione. La determinazione dei sostantivi è indicata principalmente attraverso suffissi (uscite), alle quali si affiancano anche alcune forme vere e proprie di articolo. La prosodia evidenzia la presenza sia dell'accento, sia, in molti dialetti, di qualità tonali. Lo svedese è foneticamente interessante anche per la presenza di una fricativa dorsopalatale velare sorda, un fonema consonantico altamente instabile.
Lied (plurale Lieder) è una parola tedesca, che significa letteralmente "canzone" (o romanza). Tipicamente, i Lieder sono composizioni per voce solista e pianoforte. Talvolta, più Lieder sono uniti in Liederkreise, o "cicli", ossia una serie di canzoni (generalmente tre o più) legate da un singolo tema narrativo. Il compositore più strettamente associato a questo genere musicale è Franz Schubert, che ne compose oltre 600.
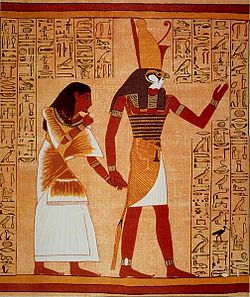
Il Libro dei morti è un antico testo funerario egizio, utilizzato stabilmente dall'inizio del Nuovo Regno (1550 a.C. circa) fino alla metà del I secolo a.C. Il titolo originale del testo, traslitterato ru nu peret em heru, è traducibile come Libro per uscire al giorno (altra possibile traduzione è Libro per emergere dalla luce). "Libro" è il termine che più si avvicina a indicare l'intera raccolta dei testi: il "Libro dei morti" si compone di una raccolta di formule magico-religiose (anche di notevole lunghezza: in un'edizione del 2008 della traduzione di Budge, il solo testo raggiunge le 700 pagine) che dovevano servire al defunto come protezione e aiuto nel suo viaggio verso la Duat, il mondo dei morti, che si riteneva irto di insidie e difficoltà, e verso l'immortalità. Fu composto da vari sacerdoti egizi nell'arco di un millennio, indicativamente a partire dal XVII secolo a.C. Il Libro dei morti si inserì in una tradizione di testi funerari che include i ben più antichi cosiddetti "testi delle piramidi", tipici dell'Antico regno (XXVII–XXII secolo a.C.) e i cosiddetti "Testi dei sarcofagi", risalenti al Primo Periodo Intermedio e al Medio regno (XXI–XVII secolo a.C.), che erano appunto inscritti su pareti di camere funerarie o su sarcofagi, ma non su papiri. Alcune delle formule del "Libro dei morti" derivano da tali raccolte precedenti, altre furono composte in epoche successive della storia egizia, risalendo via via al Terzo periodo intermedio (XI–VII secolo a.C.). I papiri delle varie copie del Libro dei morti, o di parte di esso, erano comunemente deposti nei feretri insieme alle mummie nell'ambito dei riti funebri egizi. Non vi fu mai un'edizione canonica e unitaria del Libro dei morti e non ne esistono due esemplari uguali: i papiri conservatisi contengono svariate selezioni di formule magiche, testi religiosi e illustrazioni. Alcuni individui sembrano aver commissionato copie del tutto personali del Libro dei morti, scegliendo probabilmente, con una certa libertà, frasi e formule che ritenevano importanti per il proprio accesso nell'aldilà. Il Libro dei morti era quasi sempre redatto in caratteri geroglifici o ieratici su rotoli di papiro, e talvolta decorato con illustrazioni o vignette (aventi, talvolta, un notevole valore artistico oltreché archeologico e paleografico) del defunto e delle tappe del suo viaggio ultraterreno.
Esercizi di stile (Exercices de style), scritto dal francese Raymond Queneau, è una collezione di 99 racconti della stessa storia, rivisitata ogni volta in uno stile differente. In ciascun racconto, il narratore prende l'autobus, assiste ad un alterco fra un uomo e un altro passeggero, e poi vede la stessa persona due ore dopo alla Gare Saint Lazare. Le variazioni letterarie si rifanno al famoso capitolo 33 della guida retorica del 1512 dell'umanista Erasmo da Rotterdam, De Utraque Verborum ac Rerum Copia. Gli Exercises furono pubblicati da Gallimard per la prima volta nel 1947. Nel 1963 ne uscì un'edizione aggiornata e nel 1973 un'ulteriore edizione.Il libro è stato pubblicato in Italia nel 1983 dalla casa editrice Einaudi, nella traduzione di Umberto Eco con testo originale a fronte. Una nuova edizione, con aggiunta di testi e una postfazione di Stefano Bartezzaghi è uscita nel 2001.

